Kunden & Branchen
Stöbern Sie durch unsere Projekte und lernen Sie die verschiedenen Branchen kennen, in denen wir tätig sind!
MSC Nastran FAQs

Hier erhalten Sie Allgemeine Infos zu MSC Nastran – von der Installation über eine Einführung in Nastran bis hin zu den Grundeinstellungen der Datenbank.
Wie verwende ich PARAM, POST zum Erzeugen unterschiedlicher Ergebnisdateien?
MSC Nastran erlaubt verschiedene Dateiformate für das Postprocessing der FEM Ergebnisse. Diese werden über den Parameter PARAM, POST gesteuert. Dabei bedeutet:
PARAM, POST, -1 Ergebnisse der Berechnung werden als .op2 erstellt. Einlesen bzw. Anhängen der Ergebnisse in PATRAN über Analyze – Access Results – Read Output2. Dabei wird die Datenbank ev. sehr groß; Default bei SOL101, SOL106, …
PARAM, POST, 0 Ergebnisse der Berechnung werden als .xdb erstellt. Anhängen der Ergebnisse in PATRAN über Analyze – Import Results
PARAM, POST, 1 Ergebnisse der Berechnung werden als .op2 erstellt. Anhängen der Ergebnisse in PATRAN über Analyze – Access Results – Attach Output2; Default bei SOL400
Wie kann ich Datenbankfiles (DBsets) auf mehrere Files aufsplitten?
Um z.B. das Problem der vom Filesystem (z.B. Windows 32bit FAT – max. 2GB) vorgegebenen max. Datengröße zu umgehen, können mit folgenden Einträgen im Nastran-INPUT-File (im “Executive Control Cards”-Bereich) die Datenbankfiles auf mehrerer Dateien aufgesplittet werden:
Beispiel: Aufsplitten der .DBALL-Datei auf 5x2GB-Datein: DB1, DB2, DB3, DB4 und DB5
| $ INIT DBALL LOGICAL=(DB1(2GB),DB2(2GB),DB3(2GB),DB4(2GB),DB5(2GB)) $ ASSIGN DB1=’physical file name 1′ ASSIGN DB2=’physical file name 2′ ASSIGN DB3=’physical file name 3′ ASSIGN DB4=’physical file name 4′ ASSIGN DB5=’physical file name 5′ $ |
Anmerkung:
Mit ASSIGN kann nicht nur der Name definiert werden, es kann auch der Ort der einzelnen Dateien definiert werden. Dabei kann auch auf unterschiedlichen Laufwerke verweisen werden. So kann z.B. der erste Teil auf einer schnellen SSD-Festplatte liegen, die jedoch von der Speichergrößer oftmals sehr beschränkt sind. Erst wenn dieser Teil auf der schnellen SSD-Festplatte voll ist wird auf z.B. einer langsamen SATA2-Festplatte weiter geschrieben. Es sollte vermieden werden, die Datenbankfiles auf NFS-Filesystemen (Network File Systems) zu speichern, da die langen I/O-Zeiten zu extrem hohen Rechenzeiten führen.
Während der Nastran-Rechnung werden die einzelnen Datenbanken der Reihe nach gefüllt. Wird die maximale Datengröße des letzten Files während der Nastran-Rechnung überschritten wird der Job abgebrochen (“USER FATAL MESSAGE 1012” bzw. “USER FATAL MESSAGE 1221” ).
Beispiel: Aufsplitten der .SCRATCH-Datenbanken auf 3x50GB
| $ INIT SCRATCH, LOGICAL=(SCRATCH1(50GB),SCRATCH2(50GB),SCRATCH3(50GB)), SCR300=(SCR1(50GB),SCR2(50GB),SCR3(50GB)) $ ASSIGN SCRATCH1=’nastran_job_xyz.scratch1′, TEMP ASSIGN SCRATCH2=’nastran_job_xyz.scratch2′, TEMP ASSIGN SCRATCH3=’nastran_job_xyz.scratch3′, TEMP $ ASSIGN SCR1=’nastran_job_xyz.scr1′,TEMP ASSIGN SCR2=’nastran_job_xyz.scr2′,TEMP ASSIGN SCR3=’nastran_job_xyz.scr3′,TEMP $ |
Anmerkung:
Mit dem Eintrag TEMP werden die .SCRATCH-Dateien nach Beendigung der Nastran-Rechnung gelöscht.
Anwendungsbeispiel:
| $$—————————————————–$ $$—————————————————–$ $$ Executive Control Cards $ $$—————————————————–$ $ $ $$ AUFSPLITTEN VON DBALL U. SCRATCH AUF JE Z.B. 3x100GB $$ $$ Anstatt ‘nastran_job_xyz’ kann ein beliebiger Dateiname $$ gewaehlt werden. $$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$ $ NASTRAN SYSTEM(151)=1 NASTRAN BUFFSIZE=65537 $ INIT SCRATCH, LOGICAL=(SCRATCH1(100GB),SCRATCH2(100GB),SCRATCH3(100GB)), SCR300=(SCR1(100GB),SCR2(100GB),SCR3(100GB)) $ ASSIGN SCRATCH1=’nastran_job_xyz.scratch1′,TEMP ASSIGN SCRATCH2=’nastran_job_xyz.scratch2′,TEMP ASSIGN SCRATCH3=’nastran_job_xyz.scratch3′,TEMP $ ASSIGN SCR1=’nastran_job_xyz.scr1′,TEMP ASSIGN SCR2=’nastran_job_xyz.scr2′,TEMP ASSIGN SCR3=’nastran_job_xyz.scr3′,TEMP $ INIT DBALL LOGICAL=(DBALL1(100GB),DBALL2(100GB),DBALL3(100GB)) $ ASSIGN DBALL1=’nastran_job_xyz.DBALL1′ ASSIGN DBALL2=’nastran_job_xyz.DBALL2′ ASSIGN DBALL3=’nastran_job_xyz.DBALL3′ $ $ $$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$ |
Warum gibt es Limits für Nastran Datenbankfiles und wie kann ich sie verändern (NASTRAN Memory Allocation (GALLOC))?
Auf Grund immer größer werdender FE-Modelle (> 1 Mio DOF’s ist mittlerweile durchaus üblich) kommt es manchmal zu unerwünschten Programmabstürzen. Diese sind oft auf ein Überschreiten der zulässigen Dateigröße der Nastran Datenbankfiles (DBsets) zurückzuführen (“USER FATAL MESSAGE 1012” bzw. “USER FATAL MESSAGE 1221”). Daher geben wir nachfolgend eine Kurzbeschreibung an wie diese Limits zustande kommen und wie sie verändert werden können.
1) Grundsätzliches zu NASTRAN-Datenbankfiles (DBsets)
Generell unterscheidet man zwischen zwei Arten von Datenbankfiles:
| permanente (sind für einen RESTART unbedingt erforderlich): .DBALL – in dieser Datenbank werden jene DMAP-Datenblöcke[1] permanent gespeichert, die für einen mögliche nachträgliche Rechnung (Restart) benötigt werden..MASTER – in dieser Datenbank werden die Namen aller Datenbanken, Datenbanken-Members, deren physikalischen Speicherort, etc. eingetragen.Die permanenten Datenbanken .DBALL und .MASTER sind für einen RESTART unbedingt erforderlich. |
| temporäre: Die temporären Datenbankfiles bestehen aus zwei Teilen:a) LOGICAL – in diesem werden die temporären Matrizen (Datenblöcke) des DMAP-Moduls gespeichert. Diese Einträge werden in den nachfolgenden Rechnungen benötigt.b) SCR300 – in diesem werden die Scratch-Daten der FORTRAN- und C-Routinen gespeichert.SCR300 ist ein dynamischer Bereich der während eines Nastran Laufes immer wieder gelöscht wird, während LOGICAL bis zum Ende des Laufes anwächst. |
2) Maximal erlaubte Größe der Datenbankfiles (DBsets)
NASTRAN beschränkt per Default die maximal erlaubte Datengröße der permanenten (.DBALL) und temporären (LOGICAL, SCR300) Datenbanken. Die maximalen Werte sind dabei vom Betriebssystem, dem vorhandenen Arbeitsspeicher (MEM) und im Nastran definierten BUFFSIZE abhängig. Der default-Wert von BUFFSIZE beträgt 8193, das Maximum von BUFFSIZE ist mit 65537 beschränkt. Zu beachten ist dabei, dass nicht jeder beliebiger Wert für BUFFSIZE definiert werden darf. Der Wert muss der Gleichung n*(1024)+1 entsprechen.
Laut “MSC Nastran 2012.2 Installation and Operation Guide – Table 4-5” werden folgende BUFFSIZE-Werte empfohlen:
| Degrees of Freedom |
BUFFSIZE |
| DOF < 100000 |
8193 |
| 100000 < DOF < 200000 |
16385 |
| DOF > 400000 |
32769 |
Die maximale erlaubte Größe der .DBALL- und .SCRATCH-Datenbanken in Abhängigkeit vom System, Memory und BUFFSIZE sind folgend zusammengefasst:
|
Default Maximum .DBALL and .SCRATCH DBset Sizes in GB for Specific BUFFSIZE Values |
||||
|
System |
Memory (MEM) |
BUFFSIZE |
||
|
8193 |
32769 |
65537 |
||
|
i8/ILP64 |
MEM < 256 MB |
7,63 GB |
30,52 GB |
61,04 GB |
| 256 MB < MEM < 512 MB |
15,26 GB |
122,07 GB |
244,14 GB |
|
| MEM > 512 MB |
30,52 GB (Default) |
244,14 GB |
488,28 GB |
|
|
alle anderen Systeme (z.B. Windows 32bit) |
MEM < 128 MB |
7,63 GB |
30,52 GB |
61,04 GB |
| 128 MB < MEM < 256 MB |
15,26 GB |
122,07 GB |
244,14 GB |
|
| MEM > 256 MB |
30,52 GB (Default) |
244,14 GB |
488,28 G |
|
Anmerkung:
Diese maximalen Werte werden, wenn notwendig, ohne Rückmeldung von NASTRAN auf den maximalen vom Dateisystem erlaubten Dateigrößen zurückgesetzt:
| FAT 16 | 2 GB |
| FAT 32 | 4 GB |
| exFAT | unlimitiert |
| NTFS | 16 TB |
| XFS | unlimitiert |
Aus der Tabelle ist ersichtlich, dass sich bei den Nastran-Default-Werten (BUFFSIZE = 8193 und MEM > 256 MB) eine Beschränkung der Filegröße von 30,52 GB ergibt. Bei den heutzutage immer größer werdenden FE-Modellen (> 1 Mio DOF’s) wird diese Default-Beschränkung überschritten und der Job abgebrochen (“USER FATAL MESSAGE 1012” bzw. “USER FATAL MESSAGE 1221”). Eine Abhilfe liefert das Definieren einer größeren BUFFSIZE z.B. im Nastran-INPUT-File (siehe nachfolgendes Beispiel) oder im Nastran Konfigurationsfile (nast.ncf). Eine weitere Möglichkeit ist es die max. Größe der Datenbankfiles direkt festzulegen, siehe hierzu “Direkte Festlegung der max. Größe der Datenbankfiles (DBsets) im INPUT-File”
Beispiel: Definieren der BUFFSIZE im Nastran-Input-File (“Executive Control Cards”)
| $ NASTRAN BUFFSIZE=32769 $ |
Anmerkung:
Wenn man nachfolgendem Eintrag im Nastran-Input-File (“Executive Control Cards”-Bereich) setzt, wird (falls LOGICAL die maximale Größe erreicht hat) SCR300 für weitere LOGICAL-Dateneinträge benutzt:
| $ NASTRAN SYSTEM(151)=1 $ (Default: NASTRAN SYSTEM(151)=0). |
Bitte versuchen Sie zuerst BUFFSIZE zu verändern. Wenn das funktioniert benötigen Sie keine weiteren Informationen.
Ansonsten finden Sie nachfolgend Beispiele zum direkten Festlegen der Größe der Datenbankfiles.
3) Direkte Festlegung der max. Größe der Datenbankfiles (DBsets) im INPUT-File
Mit dem INIT Eintrag im Nastran-Input-File (im “Executive Control Cards”-Bereich) kann die Größe der Datenbanken direkt festgelegt werden, unabhängig von BUFFSIZE.
Beispiel: Mit folgenden Einträgen wird die max. Größe der Datenbanken .DBALL, LOGICAL und SCR300 auf 200GB gesetzt:
| $ INIT DBALL LOGICAL=(DBALL(200GB)) INIT SCRATCH LOGICAL=(SCRATCH(200GB)) SCR300=(SCR300(200GB)) $ |
4) Direkte Festlegung der max. Größe der Datenbankfiles (DBsets) beim Submit
| Nastran inputfile sdball=1Tb sscr=1Tb |
Vergrößert die .DBALL, LOGICAL und SCR300 auf 1Tb (erlaubte Einheiten: kb,mb,gb,tb)
___________________
[1] MSC Nastran stellt eine Vielzahl an Solution-Sequenzen bereit. Jede dieser Sequenzen besteht aus einer Reihe von DMAP-Statements (Direct Matrix Abstraction Program).
Was ist der Unterschied zwischen RBE2- und RBE3-Elementen?
Ein RBE2-Element ist ein starres Element. Der Referenzpunkt (independent node) gibt die Verschiebung der anderen Knoten (dependent) des Elements vor. Die über das RBE2-Element verbundenen Knoten sind kinematisch so gekoppelt, dass sie keine relativen Verschiebungen und Rotationen zueinander ausführen.
Werden bei einem RBE2 unterschiedlich steife Anbindungspunkte gewählt, so sind die resultierenden Kräfte an diesen Punkten auch unterschiedlich. Beim RBE3-Element geben die Verschiebungen der angebundenen Knoten (hier jetzt independent nodes) die Verschiebung des Referenzknotens (hier jetzt dependent node) vor. Die Kopplung zueinander erfolgt auf Grund einer gewichteten Interpolationsfunktion und ist von den gewählten Freiheitsgraden abhängig.
Das RBE3-Element führt zu keiner künstlichen Versteifung des Systems. Die Elementknoten können sich zueinander verschieben. Diese Elemente werden daher für eine gleichmäßige Kraft- und Masseneinleitung verwendet. Im Gegensatz zu dem RBE2-Element führt eine Verbindung von unterschiedlich steifen Anbindungspunkten trotzdem zu gleichmäßigen Kräften an diesen Punkten, entsprechend der Lage zueinander.
Hinweis:
Bei RBE3-Elementen wird ein “Dependent-Node” (Referenzknoten) und ein oder mehrere Independent-Nodes gewählt. Es ist zu beachten, dass die Freiheitsgrade der “Dependent-Nodes” bei der FE-Berechnung aus dem Gleichungssystem eliminiert werden. Aus diesem Grund darf der Referenzknoten eines RBE3-Elements nicht Referenzknoten eines weiteren RBE3-Elements sein. Darüber hinaus dürfen auch keine Randbedingungen und “Multipoint Constraints” auf diesem Referenzknoten definiert sein.
Wie kann ich mehrere Nastran Berechnungen nacheinander starten ("Batch rechnen")?
Nachfolgend finden Sie zwei ZIP-komprimierte Ordner mit Files und Anleitungen für die Ausführung von Nastran, Abaqus und LIMIT im Batch-Modus unter Windows bzw. Linux zum Download.
Kann ich eine Nastran-Berechnung auch ohne .DBALL- und .MASTER-Ausgabe starten?
Nein, es wird bei jeder Berechnung ein .DBALL- und .MASTER-File ausgegeben. Da die zwei Output-Files meist große Datenmengen verursachen, empfiehlt es sich, diese nach Beendigung der Berechnung zu löschen wenn diese nicht mehr benötigt werden (z.B. kein Restart erforderlich). Durch Starten von Nastran mit dem Parameter ‘scr=yes’ bzw. durch den Eintrag ‘scratch=yes’ im Konfigurationsfile, werden nach Beendigung der Berechnung die Datenbank-Files automatisch gelöscht.
Beispiel: nastran scratch=yes jid=test.bdf
Welche Nastran Solution Sequences gibt es? Wie lauten die zugehörigen Id's?
Bei MSC Nastran wird in der Regel über Solutions Sequences und nicht wie bei anderen Programmen über die Art der Berechnung (Linear Statik, Beulanalyse,…) gesprochen. Die verwendeten Solution numbers können jedoch den Berechnungsarten zugeordnet werden. Die bekanntesten sind:
| SOL 101 … Lineare Statik |
| SOL 103 … Eigenfrequenzen |
| SOL 105 … Lineares Beulen |
| SOL 106 … Nichtlinear oder lineare Statik |
Die nichtlineare Berechnung mit SOL106 wurde in den letzten Jahren nach dem Kauf von MARC durch eine neue implizite nichtlineare Berechnung erweitert. Diese heißt jetzt SOL400 und entspricht einer Implementierung des MARC Solvers in MSC Nastran.
Ein Auszug der verwendeten Solution Sequences wird nachfolgend aufgelistet:
| SOL Number | SOL Name | Description |
|---|---|---|
| 101 | SESTATIC | Statics with options: Linear steady state heat transfer. Alternate reduction. Inertia relief. |
| 103 | SEMODES | Normal modes. |
| 105 | SEBUCKL | Buckling with options: Static analysis. Alternate reduction. Inertia relief. |
| 106 | NLSTATIC | Nonlinear or linear statics. |
| 107 | SEDCEIG | Direct complex eigenvalues. |
| 108 | SEDFREQ | Direct frequency response. |
| 109 | SEDTRAN | Direct transient response. |
| 110 | SEMCEIG | Modal complex eigenvalues. |
| 111 | SEMFREQ | Modal frequency response. |
| 112 | SEMTRAN | Modal transient response. |
| 114 | CYCSTATX | Cyclic statics with option: Alternate reduction. |
| 115 | CYCMODE | Cyclic normal modes. |
| 116 | CYCBUCKL | Cyclic buckling. |
| 118 | CYCFREQ | Cyclic direct frequency response. |
| 128 | SENLHARM | Nonlinear Harmonic Response. |
| 129 | NLTRAN | Nonlinear or linear transient response. |
| 144 | AESTAT | Static aeroelastic response. |
| 145 | SEFLUTTR | Aerodynamic flutter. |
| 146 | SEAERO | Aeroelastic response. |
| 153 | NLSCSH | Static structural and/or steady state heat Transfer analysis with options: Linear or nonlinear analysis. |
| 159 | NLTCSH | Transient structural and/or transient heat Transfer analysis with options: Linear or nonlinear analysis. |
| 190 | DBTRANS | Database transfer, Output Description (p. 310) in the MSC Nastran Reference Manual. |
| 200 | DESOPT | Design optimization. |
| 400 | NONLIN | Nonlinear Static and Implicit Transient Analysis and all linear sequences from statics, modes, frequency, and transient inclusive with perturbation analysis based on previous nonlinear analysis |
| 600 | SESTATIC (see SOL 600,ID,143) |
MSC Nastran API into MSC MARC nonlinear |
| 700 | NLTRAN (see SOL 700,ID,163) |
Nonlinear Explicit Transient Analysis |
Welche Input-File-Parameter sollte man im Nastran Input-File nicht verwenden?
Sämtliche Parameter stehen im Input (.bdf; .dat) File. Bitte suchen Sie im File nach ‚PARAM‘
| PARAM, AUTOSPC, YES Damit werden Freiheitsgrade, die im Modell vom Benutzer NICHT definiert wurden, künstlich festgehalten. AUTOSPC = automatische Single Point Constraints = Automatische Randbedingungen. Erfahrene User wollen das in der Regel nicht, da damit das Modell künstlich festgehalten wird. default = YES |
| PARAM, BAILOUT,-1 Bitte verwenden Sie diesen Parameter nur in Ausnahmefällen (!). Nastran rechnet hier trotz (nahezu) singulärer Steifigkeitsmatrizen. Die Ergebnisse sind dann oft unrealistisch. default = 0 |
| PARAM, MAXRATIO,1.E15 MAXRATIO ist eigentlich der Kehrwert von BAILOUT. Ein MAXRATIO von z.B 1.E15 bedeutet, dass Sie Singularitäten / Mechanismen rechnen; dies in aller Regel ungewollt. default = 1.E5 |
Was ist der Unterschied zwischen einem .bdf- und einem .dat-Input-File?
Nastran an sich macht keinen Unterschied zwischen der Endung .bdf und .dat. Die Endung .bdf steht für “Bulk Data Input” oder vereinfacht DATA Deck (.dat). Streng genommen stehen im .bdf-File nur die Einträge der Bulk Data Section (Knoten, Elemente, Kräfte, etc.), im Gegensatz zum .dat-File, in dem der gesamte Input steht. Jedoch wird auch häufig der gesamte Input in das .bdf-File geschrieben (der Nastran-Job rechnet auch so).
Wie kann ich die Größe der Output-Files verringern?
Nastran erzeugt in der Regel drei Filetypen, die große Files ergeben können:
| .DBALL / .MASTER Mehr Infos |
| .op2 / .xdb Die Ergebnisfiles, in die man die Ergebnisse schreibt die man haben möchte. |
| .f06 Dieses File gibt alle von Nastran angegebenen *WARNING* und *FATAL* Meldungen an und wird daher in der Regel als Erstes zur Fehlersuche verwendet. |
Im .f06-File ist eine sinnvolle Dateigröße daher besonders hilfreich um ein (rasches) Editieren zu ermöglichen!
Als default-Einstellung werden beim Nastran-Output folgende Parameter in der Case Control Section gesetzt:
STRESS(SORT1,PRINT,REAL,VONMISES,CENTER)=ALL
Dabei bewirkt der Parameter PRINT, dass die Spannungswerte auch in das .f06-File geschrieben werden. Grundsätzlich ist das jedoch nicht notwendig. Das Setzen des Parameters PLOT anstatt PRINT bewirkt, dass die Spannungswerte nicht in das .f06-File geschrieben werden. Dies bewirkt eine deutliche Verringerung der Datengröße der Output-Files.
Beispiel:
STRESS(SORT1,PLOT,REAL,VONMISES,CENTER)=ALL
Der Eintrag “ECHO,NONE” in der Case Control Section bewirkt, dass keine Kopie der Bulk Data Section in das .f06-Output-File geschrieben wird und vermindert so die Datengröße.
Der Eintrag “AUTOSPC (NOZERO)=YES” bewirkt, dass die Knoten mit einem Steifigkeitsverhältnis = 0 (GPST = Grid Point Singularity Table = 0) nicht in das .f06-Output-File geschrieben wird und vermindert so die Datengröße.
Wie ist das Nastran Input-File aufgebaut?
Das Nastran Input-File besteht aus fünf Abschnitten:
| Nastran Statement (optional) Hier können die Standardsystemparameter geändert werden. z.B. Buffergröße, Größe des Hauptspeichers, etc. |
| File Manager Section (optional) Hier können ext. Dateien, Datenbanken etc. zugewiesen werden (z.B. für Restart notwendig) |
| Executive Control Section (erforderlich) ID A,B (erster Eintrag in Executive Control Section, optional) Definition der SOLUTION SEQUENCE mittels SOL ‘Id’ Definition von Solution-Modificationen, Systemdiagnosen, Zeitdefinitionen, etc.CEND (beendet die Executive Section und definiert den Beginn der Case Control Section) |
| Case Control Section (erforderlich) Definition der Lastfälle (SUBCASE,…) Definition der Ausgabe (.op2, .f06,…) etc. |
| Bulk Data Section (erforderlich) BEGIN BULK (beendet die Case Control Section und definiert den Beginn der Bulk Data Section) Definition des FE-Netzes (Knoten, Elemente) Definition von Properties, Material, etc. Definition von Lasten, Randbedingungen, Zwangsbedingungen, etc.(Reihenfolge der Bulk Data Einträge ist beliebig) ENDDATA (Letzter Eintrag im Input File) |
Anwendungsbeispiel:
$ NASTRAN input file created by the Patran 2012.2 64-Bit input file
$ translator on June 20, 2013 at 10:59:04.
$ Direct Text Input for Nastran System Cell Section $$$ BEGIN NASTRAN STATEMENT
$ Direct Text Input for File Management Section $$$ BEGIN FILE MANAGER SECTION
$ Direct Text Input for Executive Control
$ Linear Static Analysis, Database $$$ BEGIN EXECUTIVE CONTROL SECTION
SOL 101
CEND
$ Direct Text Input for Global Case Control Data $$$ BEGIN CASE CONTROL SECTION
TITLE = MSC.Nastran job created on 10-May-13 at 14:45:50
ECHO = NONE
SUBCASE 1
SUBTITLE=Load_Case_0
SPC = 2
LOAD = 2
DISPLACEMENT(PLOT,SORT1,REAL)=ALL
SPCFORCES(PLOT,SORT1,REAL)=ALL
STRESS(PLOT,SORT1,REAL,VONMISES,BILIN)=ALL
FORCE(PLOT,SORT1,REAL,BILIN)=ALL
$ Direct Text Input for this Subcase
BEGIN BULK $$$ BEGIN BULK DATA SECTION
$ Direct Text Input for Bulk Data
PARAM,GRDPNT,1
PARAM POST 0
PARAM PRTMAXIM YES
$ Elements and Element Properties for region : Al_7020_100x60x4_Side_Fra
$ me
PBEAML 1 5 BOX
60. 100. 4. 4.
$ Pset: “Al_7020_100x60x4_Side_Frame” will be imported as: “pbeaml.1”
CBEAM 1 1 1 2 1. 0. 1.
CBEAM 2 1 2 3 1. 0. 1.
…
$ Elements and Element Properties for region : Al_5754_Sh_2_Cabin_Front_
$ Skirt
PSHELL 16 6 2. 6 6
$ Pset: “Al_5754_Sh_2_Cabin_Front_Skirt” will be imported as:
$ “pshell.16”
CQUAD4 99754 16 133808 133807 133839 133840
CQUAD4 99755 16 133809 133808 133840 133841
…
$ Nodes of the Entire Model
GRID 1 2078. -1269.5 154.9998
GRID 2 2078. -1269.5 135.6248
…
$ Gravity Loading of Load Set : Accel_Buffer_Upper Station
GRAV 60 0 1121.35 -.940831 0. .338877
$ Referenced Coordinate Frames
ENDDATA 4120f8b6
Wie kann ich eine Nastran Berechnung mit mehreren CPU's starten ("parallel rechnen")?
Um mit MSC Nastran parallel rechnen zu können, muss man zwischen SMP und DMP Analyse unterscheiden:
SMP = Shared Memory Parallel
Es wird auf einem Rechner mit mehreren Cores und einem Memory (gemeinsam für alle Cores) gerechnet. Ein SMP-Job auf einer CPU mit vier Cores ist ansteuerbar mit:
nastran jobname.bdf parallel=4
nastran jobname.bdf smp=4

DMP = Distributed Memory Parallel
Es wird auf mehreren Rechnern mit (jeweils mehreren) Cores gerechnet. Jeder Rechner hat sein eigenes Memory (verteiltes Memory). Ein DMP-Job auf vier Rechnern mit jeweils einer CPU / einem Core ist ansteuerbar mit:
nastran jobname.bdf dmp=4, hosts=host1:host2:host3:host4

Welche Input File Parameter kann / soll ich zur Modellkontrolle und zum Debugging verwenden?
Executive Control Section:
GEOMCHECK SUMMARY
Testet die Geometrie des FE-Netzes und erstellt einen Bericht im .f06-File, wenn Elemente gefunden werden, die die Qualitätsbedingungen nicht erfüllen. Hier können auch vom Default abweichende Toleranzparameter angegeben werden.
Suchbegriff: “E L E M E N T G E O M E T R Y T E S T R E S U L T S S U M M A R Y”
Case Control Section:
NLOPRM OUTCTRL=(STD,INTERM) NLDBG=ADVDBG,N3DMED
Nonlinear Debug Output Control Parameters für SOL400.
OUTCTRL: Ausgabe eines .op2-Files mit reduzierten Informationen für jedes konvergierte Inkrement, dessen Output im NLSTEP Parameter angefordert wird (“INTOUT = 0” für alle Inkremente)
NLDBG: Ausgabe wichtiger Debug-Informationen zur Konvergenz- und Kontaktkontrolle im .f06-File
GROUNDCHECK(SET=(G,N,N+AUTOSPC), DATAREC=YES, (RTHRESH=0.95)) = YES
Test auf ungewollte Zwangsbedingungen und schlecht konditionierte Steifigkeitsmatrix.
Schreibt für die definierten DOF-Sets (G-SET und N-SET) je eine Tabelle mit dem Ergebnis ins .f06-File. Bei einem Versagen des Checks (FAIL) werden die Knoten mit den höchsten Grounding Forces ausgegeben.
Suchbegriff: “PASS/FAIL”
FEMCHECK = ALL
Für SOL101 und SOL400 vor allem zum Check der RBE3-Elemente (Freie Independent-Knoten).
Suchbegriff: “FmChkRBp”
AUTOSPC(RESIDUAL,NOPRINT,PUNCH,MPC,NOZERO) = YES
Mit dem Befehl AUTOSPC = YES werden singuläre oder nahezu singuläre Freiheitsgrade automatisch gesperrt. Wir empfehlen, immer AUTOSPC = NO zu setzen, da sonst Fehler im Modell kaschiert werden. Ausschließlich für Debug-Zwecke sollte AUTOSPC(…) = YES gesetzt werden. Das dabei erzeugte PUNCH-File mit einem SPC-Set (ID 999) kann zum Auffinden von singulären DOFs in den Preprocessor (Patran, Hypermesh,…) eingelesen werden.
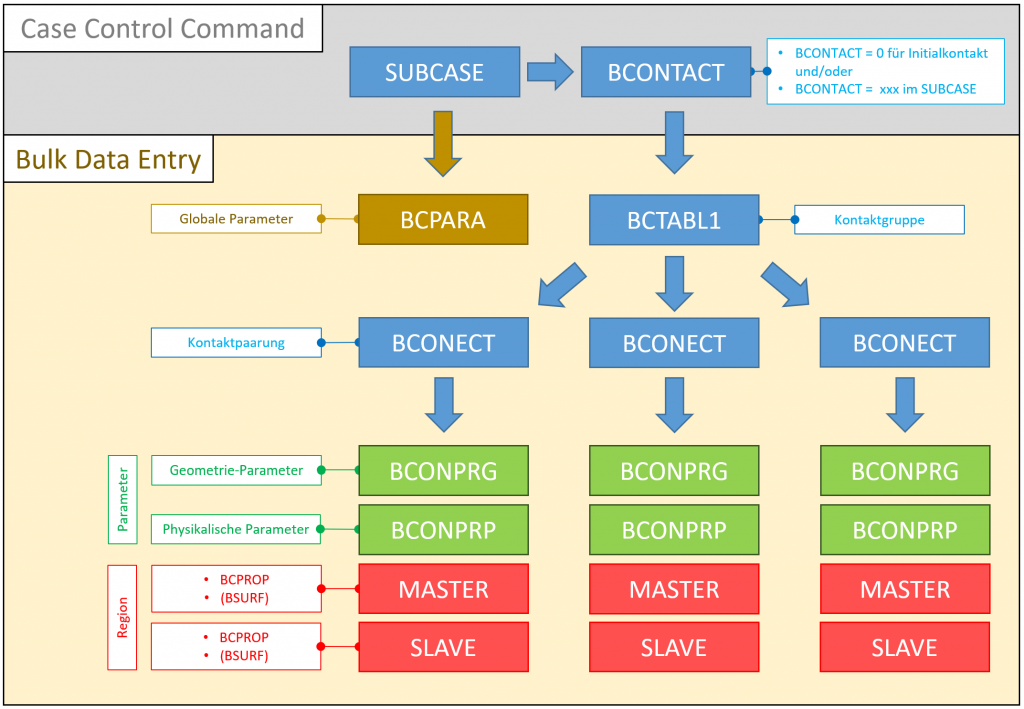
Welche Case Control Commands und Bulk Data Entries benötige ich zur Definition eines Kontakts?
Case Control Section:
BCONTACT = 0
Erzeugung des initialen Kontaktstatus, z.B. für stress-free initial contact (BCONPRG: ICOORD = 1) oder vorgespannte Verbindungen (z.B. Presspassung).
SUBCASE 10
SPC = …
LOAD = …
NLSTEP = …
BCONTACT = xxx
Zuweisung der Kontaktgruppe xxx zu einem bestimmten SUBCASE. Zu jedem SUBCASE kann eine neue / andere Kontaktgruppe zugewiesen werden. Für jedes BCONTACT-Statement muss ein BCTABL1 mit der entsprechenden ID (0, xxx) in der Bulk Data Section erstellt werden.
Bulk Data Section:
BCPARA 0 … …
BCPARA 10 … …
Definition der globalen Kontaktparameter für alle Kontakte eines SUBCASE (z.B. ID 10) oder für alle SUBCASEs (ID 0). Wichtige Parameter sind z.B. FTYPE, NLGLUE und METHOD.
BCTABL1 0 8001 …
BCTABL1 xxx 8001 …
Kontaktgruppe mit ID 0 für initialen Kontaktstatus bzw. xxx für den jeweiligen SUBCASE. Angabe aller zu berücksichtigenden Kontaktpaarungen. Für jede Kontaktpaarung muss ein BCONECT mit der entsprechenden ID (z.B. 8001) erstellt werden.
BCONECT 8001 3001 3002 1001 1002
Kontaktpaarung mit Angabe der lokalen Kontaktparameter BCONPRG (z.B. ID 3001) und BCONPRP (z.B. ID 3002) sowie der Kontaktkörper BCBODY1 (z.B. ID 1001 und 1002).
BCONPRG 3001 IGLUE x ISEARCH 0 ICOORD 0
Geometrische Contact Properties. Wichtige Parameter sind z.B. ICOORD, IGLUE, COPTS und COPTM
BCONPRP 3002 FRIC 0.1
Physikalische Contact Properties, Wichtig zur Definition des Reibbeiwerts FRIC
BCBODY1 1001 3D DEFORM 2001
BCBODY1 1002 3D DEFORM 2002
Definition der Kontaktkörper mit Dimension (2D/3D), Verhalten (Deformable/Ridig) und der Kontaktregion mittels BCPROP oder BSURF
BCPROP 2001 360
Zuweisung der Property von Bauteilen zu einer Kontaktregion. Achtung: Alle Bauteile mit dieser Property sind damit Teil der Kontaktregion (z.B. bei einer PSHELL für alle Bleche mit Dicke 10mm)!
BSURF 2002 … …
Zuweisung einzelner Elemente zu einer Kontaktregion.
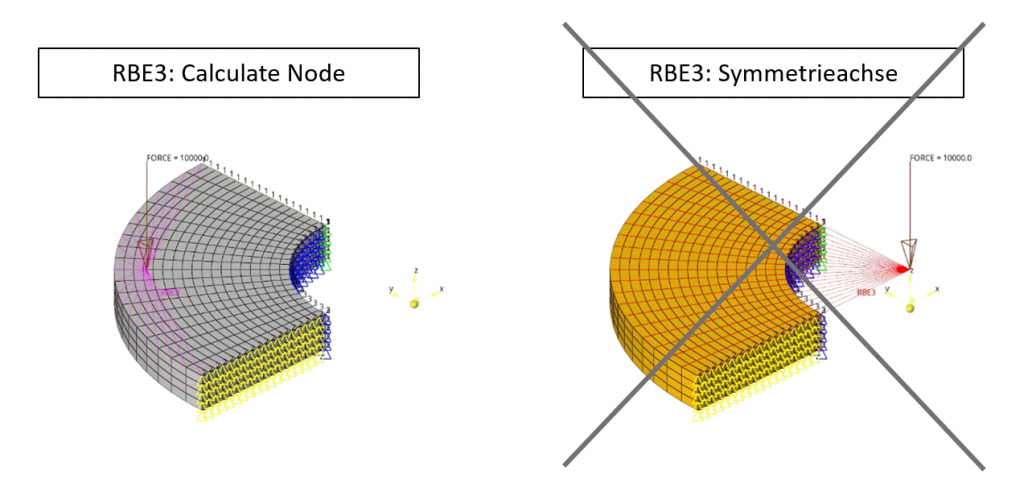
Wie definiere ich RBE3-Elemente bei Symmetrien richtig?
Die Einleitung einer Last erfolgt bei symmetrischen Modellen intuitiv in der Symmetrie-Achse. Wird eine Last aber mittels RBE3-Element eingeleitet, so kann diese Modellierung zu falschen Ergebnissen führen. Es wird daher empfohlen, den Dependent-Node des RBE3-Elements immer an der automatisch generierten Position zu belassen. Weiterführende Informationen sind dem PDF zu entnehmen.
Ansprechperson
